Building a Self-Improving Agent Loop for AI Quote Extraction
learnings from applying autoresearch to product development and why it matters
I just set up a self-improving research agent to optimize the accuracy of a document extraction pipeline in a procurement tool I'm building, and I think it might be one of the coolest things. It took the extraction accuracy from 76% to 97%, but it means a lot more than that.
This post covers how I built the self-improving AI loop, the philosophy behind why it worked, and what the implications are when you start thinking this way about any product problem (with caveats). If you just want to apply a similar approach in your own AI product, skip to Try it yourself.
For context
I'm building a tool for teams in a document-heavy B2B industry. These teams receive dozens (sometimes 100s) of unstructured vendor PDFs per project, and someone has to manually extract, organize, compare, and review that data for spec compliance before making decisions. It's tedious, error-prone, and limits the number of projects a single person can handle.
The first step we focused on is the extraction itself: taking raw vendor PDFs and turning them into structured, comparable data to find the cheapest, compliant quote. The risky part (how could the product fail?) for this core step, despite the UI and the workflow also having value, is: can the AI actually extract usable data from messy real-world vendor PDFs well enough to be usable? If that doesn't work, nothing else either upstream/downstream matters.
What I learned from doing things wrong
I've been using AI to build products for years and recently, building AI products themselves. I've learned a few things along the way.
First, start narrow. The first version should solve the smallest slice that adds immediate, tangible value. It's too easy to let a small prototype with potential explode into a complex product that does countless things, but not one single thing great. If you've lost the ability to clearly articulate the value prop of what you're building in one sentence, you've gone too wide.
Second, get verifiable data. If the AI outputs (assuming you're building an AI product) can't be checked against data that explains the right/good decision and the reasoning behind it, it won't work. I've been burned by thinking an initial dataset was enough, to later find myself relying too much on implicit knowledge to guide the AI. If you can't explain the reasoning behind a decision, the AI won't reliably either. This helps close the last 10%, making a product usable.
Third, test the core value prop. Figure out whatever the riskiest thing is that has to be true for this product to work, and prove that first before working on other things. In this case, I identified the individual value props that made this product valuable, picked the most impactful one, and shaped it into the smallest possible slice with real, verifiable data (document extraction).
To recap: pick the smallest slice that delivers a core value prop and tests one core risk, get verifiable data for it, and then don't move forward until the user can actually use it.
These are three ideas that led to the loop below.
The 3 things the model needs
The models are incredible. Superhuman. They're capable. What they need is:
1. A verifiable, vetted benchmark
I did this manually by going through the dataset and extracting/structuring it perfectly. Not sure you can outsource this part, at least not in full, and at least not yet (in most cases, probably).
2. Scaffolding and structure to run the loop
This is the technological unlock in terms of the models already having the ability to reason effectively, but they just need the structure: instructions, run-time tools, tracing visibility, and a proper feedback loop to be recursive and self-improving. The scaffolding is effectively a way for a human to define a goal with a singular metric to optimize for (as a means for achieving that goal), a method for scoring that metric based on a test that runs against your actual product, and a program that continually runs that test until a user-defined threshold is met. The agent then acts as a scientist: investigating your product code, forming a hypothesis, making a single-variable change, reading the results, and deciding to keep or discard before iterating again.
Beautiful.
3. Specific domain knowledge
This is where you need to put in your specific domain knowledge and judgement or else the agent can optimize on the wrong things and arrives at something that looks right but is not reliable + generalizable.
For example: the model was originally picking up an internal vendor reference number as a standardized product identifier. For this task, the internal vendor codes are irrelevant when comparing documents across vendors. Including them would mislead the model into thinking it had found a meaningful part number match. That was domain knowledge I had to bake into the logic. The model can't be trusted to know that on its own.
The process: how I iterated
This is probably the most useful part. Not because the specific steps are novel, but because you need to think critically about each step to separate a real improvement from a misleading result.
Prereq: The scaffolding
tldr; I adapted Karpathy's autoresearch loop to product development. The short version: you define a program.md file with a goal, a primary metric, a passing threshold, guardrails, and the files the agent is allowed to edit. The agent reads the program, runs the benchmark against your live product code, proposes a hypothesis, makes a bounded change, re-measures, and keeps or discards. Every run gets logged to an append-only ledger. It's the scientific method discussed before, automated. (the skill I created at the bottom can set it up for you)
Step 1: Manually review the baseline (your judgement + domain knowledge)
This is a key step, and something you should put real effort into. Make it programmatic and review any AI-generated decisions here since they can't fully be trusted.
I created a visual JSON reviewer to inspect the initial parsed data, confirming that field mappings were correct and that expected results matched my entity understanding.
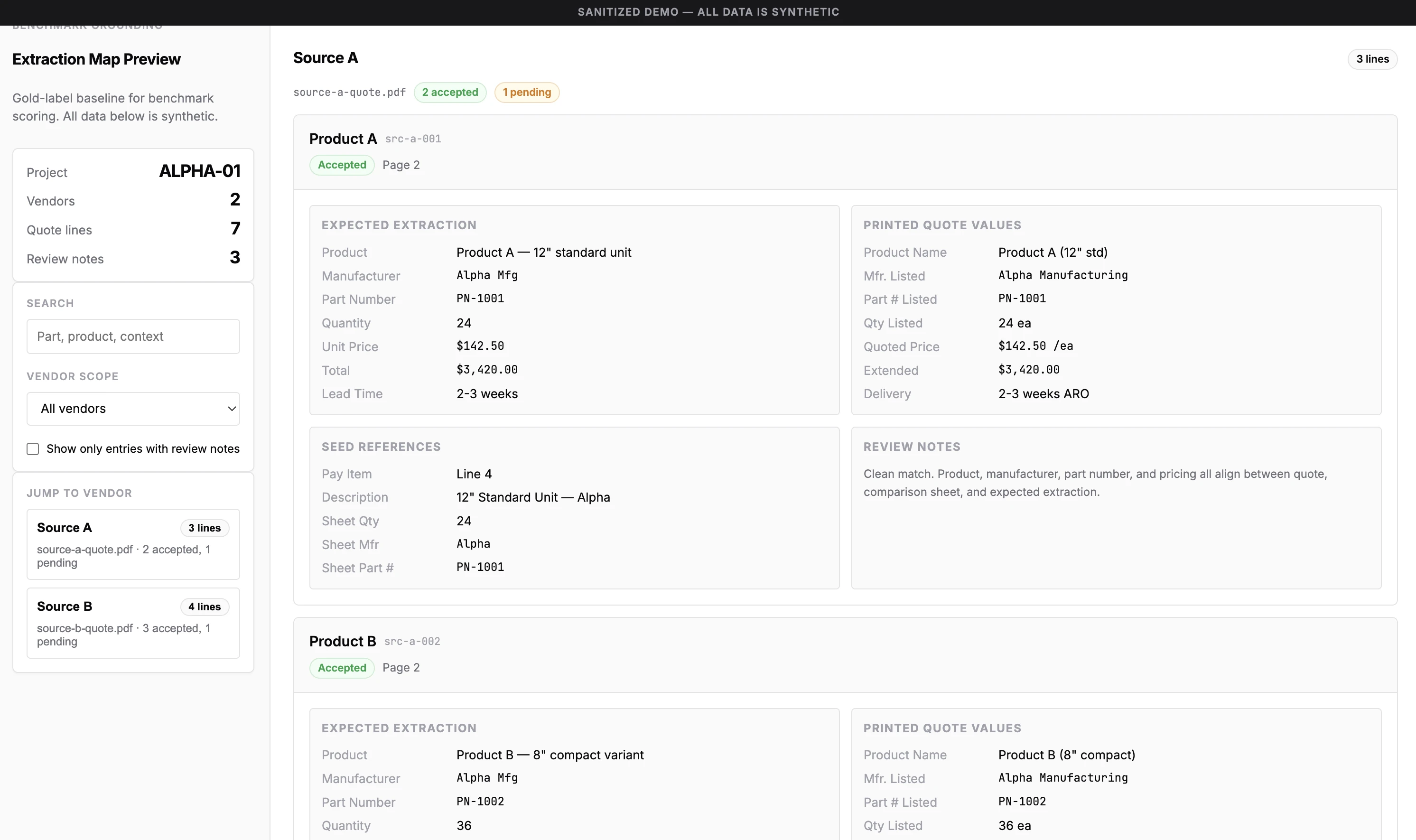
In this case, I marked every data point as either "reviewed and confident" or "needs stakeholder clarification." I wasn't the domain expert for the area this product serves, so I created specific follow-up questions to ask about the gaps. Those gaps got resolved later and improved the benchmark even further.
Post-edit: I've since created an interactive, browser-based dataset builder where I/stakeholder can create, edit, and validate the mapping of previously unlabeled artifacts, and then export it in the exact format the benchmark consumes. If you're doing something manually and repeatedly, that should be a trigger. Also, getting good baseline data is important for these tests. So I made the getting the important thing easier.
Step 2: First benchmark results
The first benchmark ran after some architecture changes (model upgrade, moving math out of the model's reasoning reqs into deterministic code) and the score went up to 81% overall from 76%. Progress.
But I looked closer.
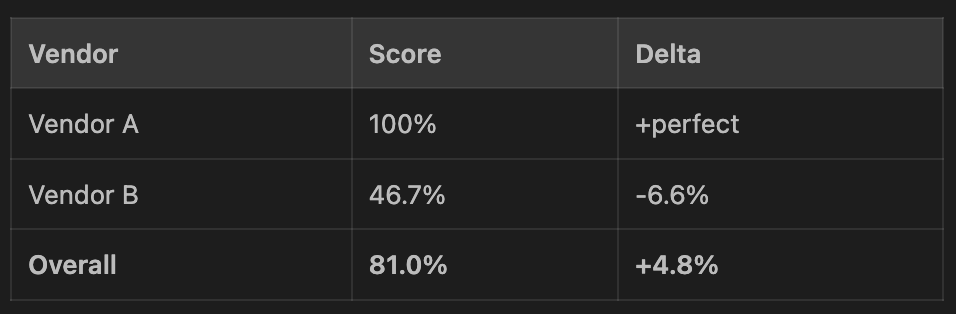
Vendor A carried the average while Vendor B got worse. Without per-vendor segmentation, that regression would have been completely invisible. The headline number would have made it look like everything was improving — a note to ensure your experiment design can call out important discrepancies like this.
This is what I mean by critical thinking.
Step 3: First autoresearch loop with cheap win
I ran the first autoresearch loop and, wow, it worked! Twas a cool moment to think about how I effectively just hired a smart scientist. It came back at 100% on the rows I had accepted the baseline data for.
When I looked at what actually changed, I saw prompt adjustments and few-shot examples shaped around the current data. Few-shot examples are prompting 101. With a limited dataset (13 accepted rows), I knew to be wary. This won't generalize to more projects.
Time to revisit the loop design.
Step 4: More agency, more ownership, more judgment
I wanted to increase the performance of the loop so the agent wouldn't go for cheap wins. The problem I saw was that the agent was only allowed to edit the extraction prompt. Which, of course, led it to a cheap win with the examples. So I increased its ability to make change.
I gave the agent access to edit the extraction agent configuration, tool definitions, schemas, and the ability to create new files as it saw fit. BUT more agency requires more trust, and more trust requires more context. So I did two things:
Gave it architectural context. I pointed it to read a spec explaining every product and architecture decision with its rationale, so the agent could reason about why the code looks the way it does currently before changing it. Without this, it would make changes that technically improve the score but violate my intent.
Gave it design principles. Things like "model agency over rigid rules" (because it's a bet on model capability vs rigid code that gets removed at the next model release). These principles came from lessons I've learned from past product builds. They detail how the agent should think about changes, not just what it can change.
Step 5: Closing open questions with the domain expert
A 20-minute call with the domain expert to walk through the uncertain data points in the baseline was all it took to get clarity on the remaining items. Key to ask for evidence and deeper relationship/alternative/exception understanding instead of confirming if something is right.
That 20-minute conversation surfaced domain knowledge the model wouldn't arrive at on its own.
New ontology on field-level semantic ambiguity, what certain identifiers actually mean in practice, how related fields interact, and how to handle edge cases became a new experiment direction for the autoresearch loop. That knowledge would help the model reason about future cases.
This is the part of the process you can't skip. Take the time to ask the question and get a real answer.
Step 6: Increasing expectations
Every time I proved the approach worked and got more confident in the baseline dataset, I made it harder by raising the success threshold.
80% → 85% → 95%. (with individual vendor thresholds too!)
Once I knew the approach worked, I raised the bar on quality. The weakest vendor had to improve too, not just the average.
Results
97%. Tested in production. It works.
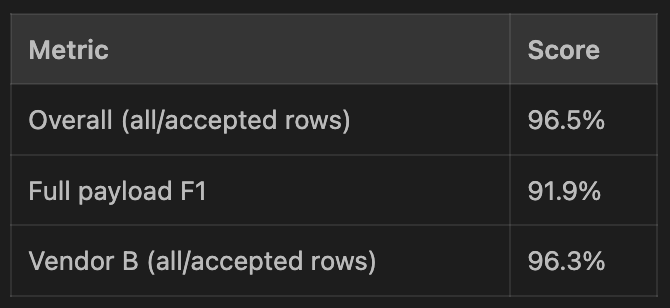
The next meaningful rerun is when a second project dataset is added, because the main open question is how well it can generalize across more than one project's vendor mix.
The caveat
Although this feels magical (it is), it's a scientific process. It depends on having a narrow, well-defined task and trustworthy evaluations. In my case, the next step is to introduce another real project's data so the loop optimizes across a variety of formats and vendors.
The beauty of it is that all I need to do now is upload that dataset, create a new baseline, and then tell autoresearch to optimize for it. It'll do the rest.
Why this matters
If you can define a verifiable benchmark for what good looks like, you can run an agent in a loop to optimize against it.
What makes this powerful is not that the agent is smart (I'm already taking this for granted), it's that the loop is scientific and "good" is accurately defined.
Another awesome thing is that this isn't technologically hard for anyone to do. It's an understanding problem and a critical thinking problem. You need to understand the process, understand what "good" looks like for your specific domain/problem you're solving, and think critically at each step. In practical terms, this process helps automate the last 90% (the hardest part) that turns an AI feature demo into something that actually works.
The implications of operating this way are grand (i.e. finding a problem/process you care about that needs improvement, defining what good looks like and what the goal and metric to optimize for is, then having AI run in a loop). The scientific process itself isn't new. But now we all have access to an AI that can run in a loop, on its own, 24/7, with PhD-level intelligence. And it's cheap. And it's getting cheaper. And it's getting better. Really fast.
Imagine a loop_improve(humanity). Obviously, it's a lot more nuanced than that (an understatement, yes), and there's untouchable beauty in the unquantifiable. But I believe we're most certainly in some type of loop (always have been?), and it's super leaky, but now we have easy access to near-endless ambition to solve problems we care about. It's hard to really grasp at times. It's moments like these where learnings are really crystallized. The potential impact of AI continues to blow me away.
One more important thing I've continually found to be true is that this stuff never really sticks unless I do it myself. For example, I've read about the autoresearch method before, I wrote about my thoughts and progress on building similar scaffolding, but it wasn't until I really built my own self-improving loop with tangible, measurable impact on a real product that I felt it. This seems obvious. Because it is. And the easiest way to see the obvious is to do it.
So here's how you can do it ->
Try it yourself
I built a companion skill to download that walks you through setting up a similar autoresearch loop in your own AI product. It starts by verifying whether you even need one to begin with (and if you do, can you verify results with real data?), and then guides you through identifying your risky, high-value AI surface, creating the benchmark, building the program file, and running your first loop.
Copy this into your AI coding agent (Claude Code, Codex, Cursor, etc.):
Download and run the autoresearch setup skill from https://github.com/declankra/ai-engineering. Start by reading the skill file, then guide me through setting it up for my project.
Caveat is that it's preliminary. I'll keep adding gotchas and experiment-shaped learnings from my own work, so it gets better over time across a wider range of problems. If you try it and have trouble, declankramper@gmail.com.
If you've been building with AI and have your own experience with this kind of iterative improvement, I'd love to hear about it :)