Encoding and Automating Implicit Knowledge
an operator's guide to turning expert judgement into compounding data
I built a product that encoded a midsized construction firm's implicit scoping workflow into an agent that correctly and reliably makes ~80% of the decisions (51/63, scored against what the expert actually delivered) for that process. None of those decision rules were written down prior. The workflow that used to take the expert 2.5 hours, now takes 20 minutes (5 min agent time + 15 min human review). And with each use, the accuracy gets better through a human-reviewed AI loop on production data. How did I get there? How can this be done generally for any business workflow with implicit, conceptual knowledge? This post will explain.
thesis and tldr;
This post is specifically relevant if:
- you are applying technology (AI) to improve someone else's workflow
- the workflow is recurring and valuable, but poorly documented
- the domain expert you're working with can review/correct the output before anything high-stakes is final
The main problem/question this post will answer is: How do you apply AI to a workflow when the knowledge to do it is neither written down nor in your own head?
This problem is important because most business work is not cleanly documented, yet AI presents an opportunity to do more of the job (delivering the actual outcome) by automating more of the tasks (things you do to get to the outcome).
The main thesis is: when no clean dataset exists (and it's not in your head), your job is to put the highest fidelity draft you can in front of the expert, encode their corrections, and continually raise the fidelity of that loop until it's a human-reviewed AI system running on production data that turns the expert's judgement into compounding data.
The way to do this is:
- Define the outcome the workflow exists to produce
- Collect every artifact that exists, even if it's half-completed and the expert initially assures you "we have no data"
- Continually build the quickest, highest-fidelity artifact you can that gets a reaction (aka feedback)
- Capture the delta between the latest iteration/draft and the expert's correction (aka feedback)
- Continually encode an increasingly better understanding of the workflow/ontology, while reducing rigidity in the product/tool and leaning into agent-native capabilities, so each correction gets sorted into a more composable form: a rule for the code, a judgement for the skill, or a test for the eval set
- Wrap the workflow in a human-reviewable agent loop
- Keep shrinking the delta between the agent's first draft and the human's final artifact
why this matters now
Automating the processes with clean, documented data is becoming a solved problem (one agent mention away). But not every business process is written down. Most aren't. Instead, they live in the heads of the people that do the work and in the unconnected dots of the half-completed artifacts, phone calls, hand-scribbled notes, non-descriptive emails, quick texts, and in-person conversations with their coworker. That's true of most knowledge work. A lot of consulting. And what most SMBs run on.
Here’s a visualization that illustrates the trade-off in quality/availability of data vs human effort to automate:

This chart highlights a couple things:
- there will never be 'perfect' data (curve eventually flattens because human judgement never leaves)
- less human work is required to automate when there’s more data, so a process with more data is a better candidate for effectiveness of an automation
So then why would you spend human time trying to automate something that doesn’t have data? Like many other business decisions, it’s a question of ROI: it's worthwhile if the effort spent building that automation is less than the expected returns of that automation. The point on the first graph highlights where this point of payoff exists. The kicker is that the exponential progress of AI is dramatically shifting where it lies.

The difference in this graph is that AI has lowered the effort to automate at every level of data, so (an implicit, high-pain, and recurring) workflow (with little data) that was previously not worth it, is now worth it.
It’s up to you to determine where your workflow sits on the overlay of this graph and pain / potential return. In a world with no perfect data, this post talks about a way to automate the workflows with far less than ideal data conditions, i.e. how to automate* implicit knowledge.
*The same way that there will always be human judgement required to create the automation, the automation will never be 100% either -- both will need human judgement to do the review. Think of 'automation' in this sense as a system that can make most of the routine decisions correctly enough that the human work moves from doing the workflow to reviewing the workflow.
how to do it
quick hit: picking the workflow
The starting point for the result I gave in the beginning was a business with the same question most businesses have today: "We know AI should help, but we don't know where?" My first task was to figure out which of the current problems/workflows were valuable enough to make it worth applying AI. For the midsized construction firm I worked with, it ended up being the bid submission process because it was a limiter to business growth and had the current, solvable problems of being fragmented and manually intensive.
Generally speaking, you should look for similar workflows that are artifact-driven and recurring enough to matter (daily/weekly).
So assuming you've already identified a valuable workflow and defined success (the outcome it exists to produce), the 'how' of this post is an operator's guide for encoding the expert's judgement.
operating principles
Three principles to keep in mind always:
- Feedback cycle time (shorten it)
- Closed loop system (make it)
- Obsolete yourself (as much as it makes sense)
You should start with assessing your feedback cycle time. How long does it take to get feedback? i.e. How long does it take to learn? Figure out how to speed that up and you’re winning. That’s the whole game. We’re here to learn. If there’s nothing else you take away from this, let it be that. You can stop reading now and go speed that up. But I’ll continue.
It’s the first thing because there’s no such thing as a perfectly closed system no matter how much energy you spend closing the system, and by improving your feedback cycle time, you’ll inevitably create a tighter system. And therefore, obsolete yourself. So first focus on that.
As you read, think about where we ultimately want to end up: outside of a system that can iterate on itself, using the highest fidelity form of feedback (production data), to minimize the delta between what the agent produced and what the human ultimately decided (a loss function).
This is my current working answer for one of the hardest questions in this kind of work: how do you test something that has no right answer? You can't write pass/fail tests for a judgement call. So you do the next best thing. You measure the gap between the agent draft and what the expert human actually delivered, and you drive it toward zero. The loss function is the test.
Here are the stages of what getting that feedback looked like
Every stage below was me doing the same thing: putting an increasingly higher fidelity draft in front of the expert and encoding the corrections (feedback). Those corrections became the dataset that never existed and the accumulation of that understanding became the most valuable asset I built (ontology + skills + evals).
1) questions
In the practice of applying AI to implicit business workflows, the lowest fidelity form of feedback is a question. What did you do? Why did you do that? How did you do that? What happens if you didn’t do that?
Asking some form of these questions will get the ball rolling. So this was where I started, questions in email (even lower fidelity than questions in person):

One of your questions at the start definitely needs to be: What data exists -- and can you share it with me? The answer will be on a spectrum; don't take "oh, nothing" as-is. There will be opportunities as you're walking through their current process to ask for specific artifacts. In my case, it started as one document with a couple scribbles.
2) visual (whiteboard)
Once you have a starting idea of the workflow, and a piece of data to work off of, I recommend turning it into another format, normally text -> visual. Doing so will help your own understanding but also provide a different angle or higher form of fidelity for the person you're working with to react to. More reactions to more ways of thinking about the work = more well-rounded understanding of the work = more data for the AI.
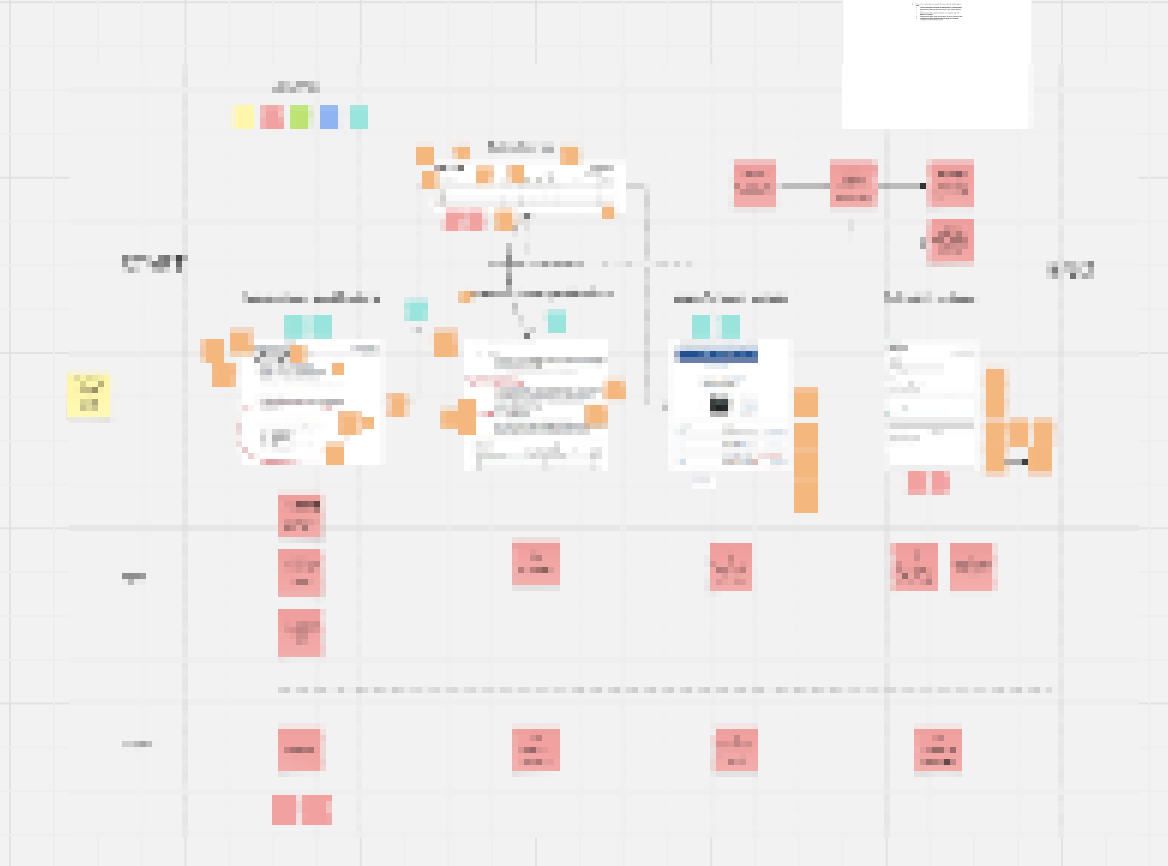
3) whichever format is best-suited for the current question
Now that you've got an understanding of the current workflow with some initial details, you'll have more specific questions. "You don't know what you don't know". So once you start knowing, there's more to know. The fun part here is that you can/should adapt the way you collect feedback based off whatever is the current problem to solve / question you have.
For example, early on a core problem I had was that there was no fully completed deliverable that captured all the decisions for a real project. No dataset that said this is what good looks like at the very end. So when I got my hands on a half-completed and non-formatted deliverable, I built a reviewable artifact that turned my best guesses of the remaining work into a visible benchmark: what the correct mapping was and why each item belonged where. This display not only visualized the decisions (making it easier for the expert to digest), but it was interactive such that during the live session I could include comments and make selections based on what I was hearing. Then, when it was time to turn that feedback into working software, I fed the edited artifact straight into the coding agent's context, so it had explicit, structured context to build from. It was the best reaction surface at the time.
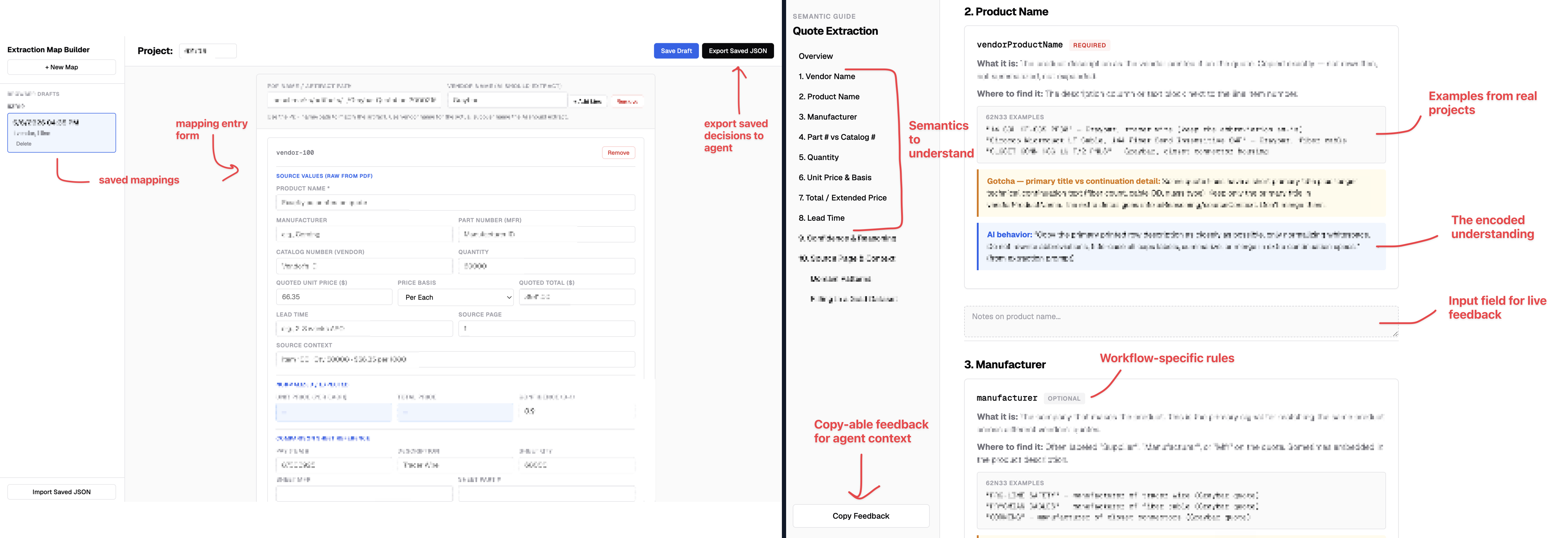
This is important in three ways:
- you're collapsing the feedback -> implementation loop by making the notes, review artifact, and technical implementation decisions one single surface
- you did the work ahead of time to make it less work for the expert at time of review
- after reviewing with the expert, you've created a golden dataset that can be used as a baseline for something like autoresearch
Later on, when the problem was figuring out an intuitive UI/UX that made sense for the workflow, I generated 3 variants of the potential interface and interaction design, created a 4th one that was my own hunch, and then got his feedback on all of them to end up with a 5th one that was usable.
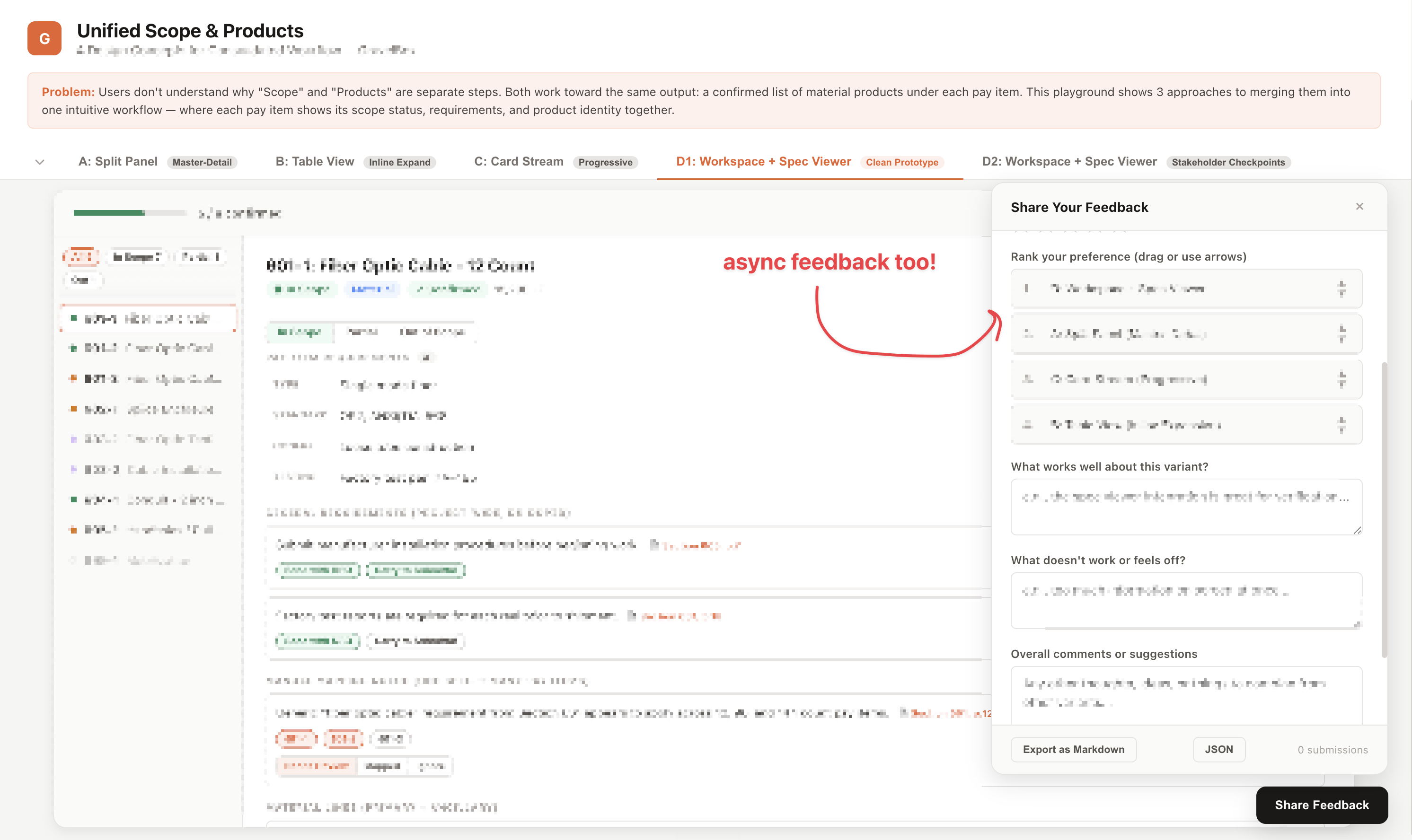
Different problems and questions, same approach: get quickest feedback in highest fidelity form you can. More data for the AI to understand.
4) rigid products that loosen over time
When first learning to ride a bike, training wheels are needed if you want to go at all. But once you know how to ride a bike, you remove them if you want to go far and fast. What was once a necessary structure has become a weight holding you back. Rigidity in AI products works the same way.
Don't make the same mistake of trying to automate the whole workflow at once in the beginning. When you have no clean labeled data and zero domain knowledge (like i did), letting the agent/product try the whole thing will fail meaninglessly because there's nothing to correct it against, so there's nothing to review, and therefore nothing is learned. An agent/model OOTB from a lab can't infer all the implicit judgement from vibes.
Rigidity early exposes ambiguity, forces specific judgement calls into the open, and makes each correction specific and attributable to one decision.
Since I also didn't have labeled data or domain knowledge, the approach I took was to: constrain/build (smallest rigid slice) -> observe/collect (every correction) -> encode (move repeated corrections into code/skill/ontology) -> expand (then move upstream / hand the agent more). When encoding, there's the latent judgement that should be written into skills vs the rules/math/validations/state that should be written into deterministic code. In judgement-heavy workflows (like the one I was dealing with), it'll feel like a 'loosening' of the product as the human corrections become data/skills and the agent is given more responsibility with room to breathe.
Two examples of how this played out in my case:
- scoping workflow: single-turn LLM API calls in a sequential step process -> sandbox agent autonomously drafts the full scope with 80% accuracy
- quote mapping workflow: agent extracts precise quotes from vendor PDFs but human manually mapped each quote line item -> agent autonomously extracts + maps each quote line item with 95% accuracy
Rigidity helps create the data that lets you remove it. A rigid product is the whiteboard's successor: the next reaction surface up in the fidelity ladder, now made of software.
5) highest fidelity: human-reviewed loop on production data
Throughout the many iterations of this feedback process, and assuming you've built the product that the expert is using on real-world projects, you'll eventually get to a point where you've encoded enough understanding of the entire workflow that:
- the agent creates a complete, expert-reviewable first draft
- the product itself captures the delta between the AI draft and the final delivered artifact (what the expert finalized)
This delta is the loss function. A loss function on expert-reviewed production data.
Then, as the builder, you can create an AI loop that analyzes these deltas -- AI draft vs expert-finalized deliverable -- to make improvements to the product that close the gap. Production learnings promoted into the ontology, skills, evals, etc. that run the workflow. The system compounds.
I initially called this a "self-improving" loop, but that's not 100% honest -- it's a human-reviewed loop. Although not as cool sounding, I think the distinction is important because (a) I am indeed reviewing the suggested changes before pushing to production and (b) models tend to be overly permissive in their own self-guided promotions which leads to worse performance over time. It's my final judgement call on what gets promoted into production and how (no slop!).1 This is based on my understanding of the user, domain, and the product -- "product sense", if you will. For example, in this workflow it's better to have more false positives than false negatives in the agent-suggested products because it's faster/better/cheaper to choose between 4 possible manufacturer/part number alternatives than shuffling through old projects manually or forgetting a more cost-efficient alternative.
This is where the system got really cool: since all of the final scoping decisions are captured in the product, the agent can now suggest exact products that aren't even in the project specification documents. Compounded proprietary data. The expert's specific, implicit business decisions are suggested even though the spec never named them; the system learned what this particular expert usually wants (what used to be only in their head). Important to note for building trust that the product should clearly label the difference between what is proved in the source project documents and what it learned as a preference.
the stack
- Agent drafts -> reviewable db and traces: The scoping agent reasons over every decision and writes them as reviewable rows, each cited back to the source page. Every step of the run is traced, so I can see how it reached each call.
- Expert commits -> delta captured: When the expert reviews and commits the scope in the product, every edit is logged as a review event (extra product, missing requirement, near-miss part, etc.) tied to that run. That's the delta: draft vs. final.
- Coding agent scores the gap -> proposes promotions: On a schedule, a coding agent pulls context (the draft, finalized decisions, traces, production logs), scores the latest run against what the expert delivered, and then proposes changes to close the difference: a gotcha for the skill, a new eval case, an ontology update, a deterministic code rule to stop a deviation.
- I review -> regression test -> ship: I decide what's slop and merge what helps. The survivors run against the new project's committed decisions and a past project so there's no regressions and then ship it so the next scoping run lands a little closer to what the expert would've done.
this is how
Earlier I asked one of the hardest questions in this kind of work: how do you test something with no right answer? This is how. The delta between the agent's draft and the expert's finalized scope is the test. On the last project it sat at 51 of 63: the number of judgement calls where the agent already matched what the expert delivered.
The benchmark also shows up in measured time, too. As that delta shrinks, so does the time spent reviewing -- obsoleting oneself from the work of yesterday.
what you're really building
If the most important outcome is a solved problem, then the process to cycle between 'understanding problem' to 'implementing solution' is core to that outcome. The tangible thing you build along the way is helpful to get there, but isn’t durable like the two things on the end: the understanding of the problem and the solution that solves it. Take care of the loop (using the three principles from the beginning) that builds that understanding. In doing so, you’ll stay agile to the inevitable changing understanding of those two ends and accumulate the prized possession: ontology.
Choose an architecture that lets you iterate on the product fastest; I found skills to be the best paradigm for conceptual work - they're the most iterative form of a tool I've used. Hand that ontology + skills to a better model in two years (or next month haha), and your product gets better.
caveats and what i'd do differently
Some specifics on what made my experience effective:
- value ≠ adoption. a solution you identify can be valuable, but unless it's actually used, it doesn't matter. i viewed progress as an adoption problem. "will you use this to start your next project? why/why not?" and that answer drove the next piece of work.
- the workflow had a benchmark. find a way to put a number on it. for abstract/conceptual work, an expert's artifacts/deliverables serve as benchmarks when you have an agent draft and can diarize the differences between the two.
- the edits to the runtime product were never 100% automated (an automation will never be). and the reason for this is more than just "a human should stay accountable" because the suggested promotions (like I talked about before) would've degraded performance without the human judgement.
- the further away you are from the work, the easier it is to fall for the one-shot prototype. the prototype only covers the happy path and true adoption needs more than that. an expert can easily tear apart a demo; this is why we're convinced an AI demo will replace the work we don't do ourselves.
- and because of that: this takes time. you need an expert willing to lend theirs, which means your job is to make the time you have with them maximally effective.
The two things I'd do differently:
- ask for more data upfront: it only makes the process faster. there were a couple times I received an artifact which would've been helpful much earlier had I sought to be more direct.
- do it in person: not only would this make the process faster, but there are discoveries that can't be learned through a video call. particularly the behavior that happens off screen (procrastinating on phone or environmental workarounds) which is another signal when creating the ideal state workflow or prioritizing.
why this matters in the bigger picture
A job is to deliver an outcome. Not to do a task. A doctor's job is to improve health, not fill out charts. As the exponential progress of AI takes over more of the tasks, it leaves more of the essential part of the job: the outcome. This has been the case with every advance in technology and I think that's a good thing. Humans can optionally still do the tasks, but they're not required.
Because AI leaves more of the essential parts of the job for the human, I believe the net result for society is that more people will be empowered to work on what they're uniquely curious about. I believe this will allow people to lean into their individuality and do more of the work they love.
But getting there isn't automatic. The world is full of business workflows like the one discussed here: painful, undocumented, yet necessary to deliver a certain outcome. And the gap between model capabilities (the potential for impact) and application within companies (potential realized) is becoming an increasingly unavoidable investment question. The easiest version of closing it is to apply AI to your own work, since you already know the work. But the person doing the work is usually heads down doing it, and can't also be specialized on the frontier (especially since it moves every week). So it takes someone from the outside, who does live on that edge, to bring it to the person doing the work without being anchored to how it's always been done.
The market is calling that person a forward deployed engineer (FDE): someone with both the communication and technical (product + engineering) skills to build the thing that actually delivers the outcome. It's the job I just walked through.
And elevating someone so they can get closer to what they want to be doing is purposeful work. That's the work I want to keep doing.
Footnotes
-
the operating principles would tell us to encode our own judgement correction-calls we make on these AI-proposed changes, to make the AI-proposed changes even more accurate, so you spend less time reviewing it. yeah. the game continues. ↩